棱镜假说深度解析:如何用一个统一潜空间同时驾驭语义与细节
三年前,我第一次尝试把CLIP和SD-VAE拼在一起做多模态任务时,训练日志里充斥着诡异的loss震荡。当时我以为是自己代码写得烂,后来才意识到这是整个视觉表示领域的底层矛盾。
语义与细节:一个被忽视的本质冲突
视觉基础模型界长期存在一个隐性分裂:语义编码器(DINOv2、CLIP)擅长类别、属性、关系等抽象信息;像素编码器(SD-VAE)擅长纹理、边缘、小字等细节重建。两条技术路线井水不犯河水,但当你真想把它们合并时,训练效率下降、表示互相干扰、最终效果四不像。
南洋理工与商汤的研究团队把这个问题追溯到更本质的层面:世界的信息到底如何被表示,才能既共享语义,又保留各模态的细粒度?他们的答案是PrismHypothesis——棱镜假说。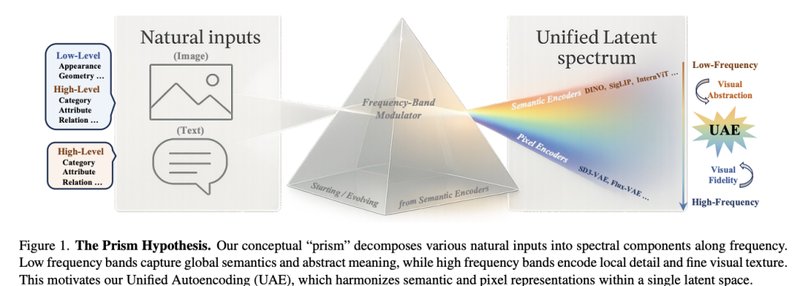
频率谱视角:低频语义、高频细节的物理映射
棱镜假说的核心洞察异常简洁:真实世界的输入可以看成投影到同一条“特征频谱”上的不同切片。低频更接近全局结构与语义(类别、布局、关系),高频更接近局部细节与质感(纹理、边缘、微小文字)。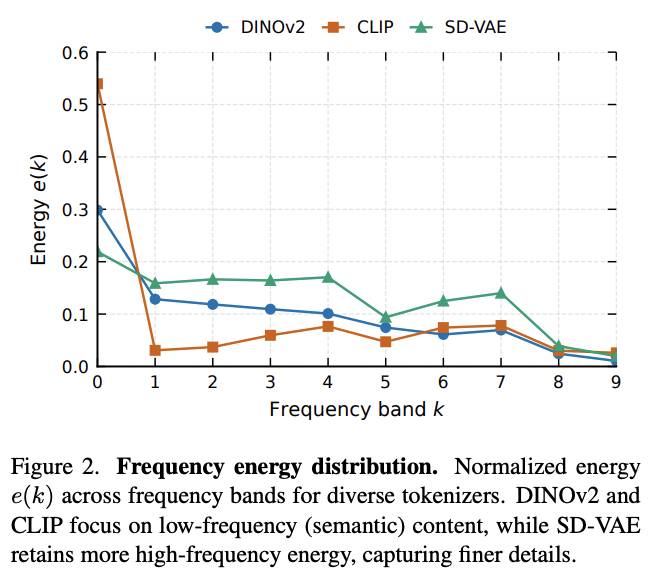
这个假说有扎实的实验支撑。能量谱分析显示,语义编码器(DINOv2、CLIP)能量集中在低频,像素型编码器(SD-VAE)保留更多中高频。频率过滤实验更具说服力:文本-图像检索的R@5在低通情况下稳定,但去掉低频基座后会直接崩塌趋近随机——这直接证明跨模态语义对齐依赖共享低频基座。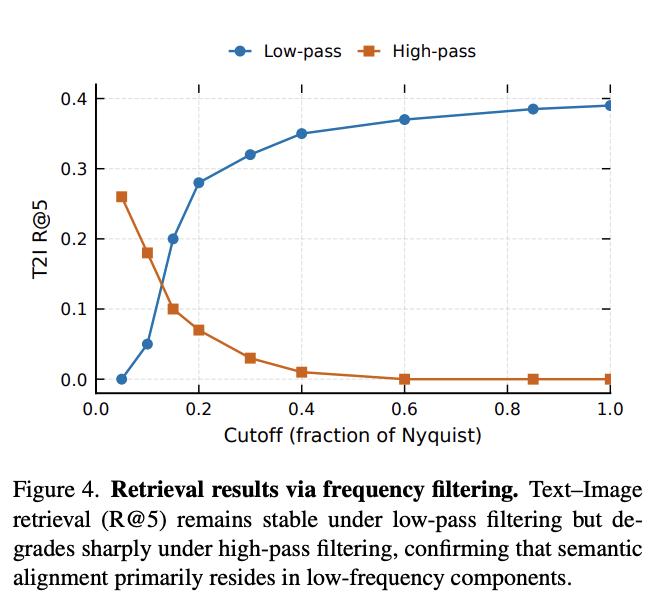
UAE方法论:频域可控的残差分带
UnifiedAutoencoding的设计思路围绕“低频语义基座+高频细节残差”展开。统一编码器从DINOv2初始化,进入频域处理阶段。关键创新在残差拆分流:使用FFT做频段投影(平滑径向mask),迭代残差拆分把潜变量分成多个频带。低频带承载语义/全局结构,更高频带逐步承载边缘、纹理等细节残差。分解必须满足可逆性且保持空间一致性。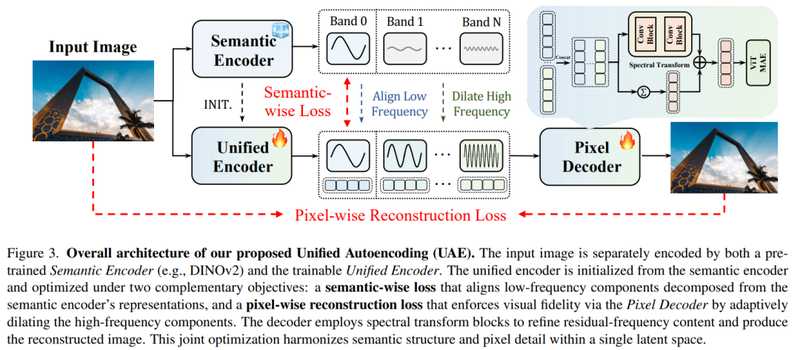
频带调制器在训练时对高频带进行噪声扰动以增强鲁棒性,随后各频带在通道维拼接作为解码器唯一输入。语义对齐损失只约束最低频的前K个band——低频对齐,高频放开学像素。这一定位明确为tokenizer,能与现有diffusiontransformers无缝对齐。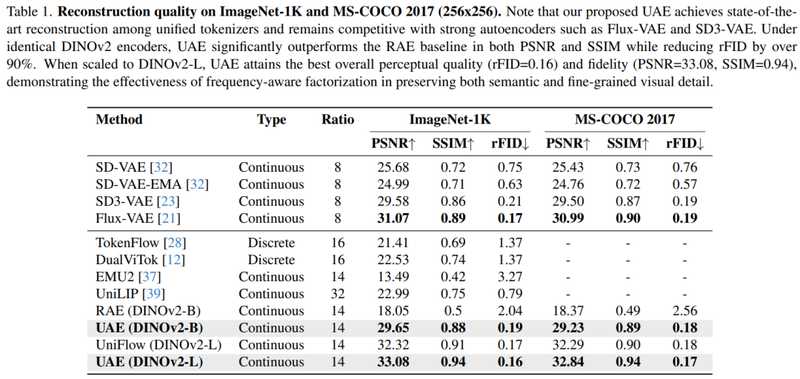
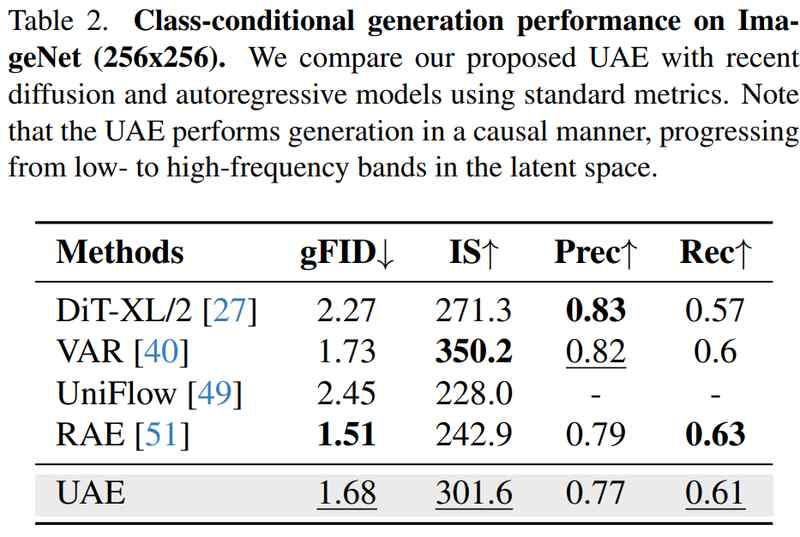
实验验证:一个潜空间的兼得命题
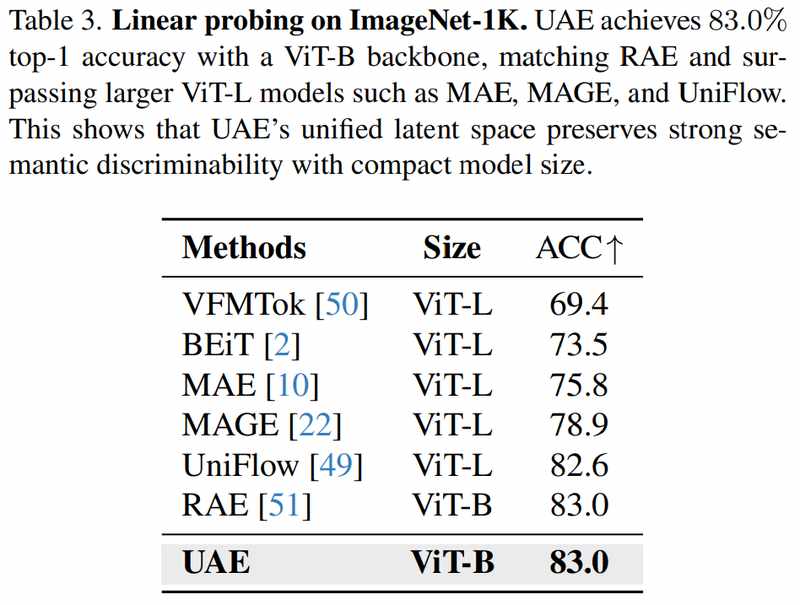
重建任务上,UAE(DINOv2-L)在ImageNet达到PSNR=33.08、SSIM=0.94、rFID=0.16,MS-COCO上达到PSNR=32.84、SSIM=0.94、rFID=0.17。相较RAE基线,PSNR/SSIM更高,rFID下降超过90%。生成能力方面,ImageNet256×256类条件生成达到gFID=1.68、IS=301.6。语义理解上,ViT-B骨干在ImageNet-1K达到Top-1=83.0%,与RAE持平。
数据说明一切:在同一个DINOv2编码器设置下,UAE同时实现了语义理解和像素重建的高水平,而不再需要在两套表示间妥协。